Training-Free Video Editing via Few-Step Streaming Video Generation
1 The University of British Columbia 2 ETH Zürich 3 McMaster University
4 Vector Institute 5 Canada CIFAR AI Chair
Although existing video editing methods are generally feasible, they often require many costly iterations and still struggle to deliver high-quality yet satisfying editing results. We attribute this limitation to the prevalent data-to-data paradigm, which is less compatible with modern generative models than noise-to-data generation.
To address this gap, we revisit video editing from a noise-to-data perspective and propose Streaming-Generation-based Video Editing (StreamGVE), which preserves few-step sampling while seamlessly injecting source-video conditions.
Built on pre-trained streaming generation models, StreamGVE introduces dual-branch fast sampling with a self-attention bridge and cross-attention grounding/boosting to satisfy both sampling and conditioning requirements. We further propose source-oriented guidance to improve target-generation quality, and a visual prompting strategy to enhance editing flexibility and practicality.
The method is effective, robust, and generalizable across different models. Extensive experiments on diverse video editing tasks show that StreamGVE consistently outperforms existing approaches, even in few-step settings with minimal time cost.
Change the dog into a seal.
Replace the man with a spiderman.
Change the color of the car to pink.
Remove the toy from the scene.
Replace the dog with a horse.
Change the bus to a jeep.
Change the red sports car to a jeep.
Replace the man with a panda.
Add sunglasses to the dog.
Change the city bus to a glass bus.
Replace the man with a robot.
Replace the swan with a paper boat.
Replace the crow with an owl.
Change the helicopter's color to fuchsia.
Replace the jacket with a dragon robe.
Replace the tiger with an elephant.
Change the coffee's color to light brown.
Replace the monkey with a red panda.
Change the color of the dress to red.
Change the thirsty dog to a goat.
Replace the dancer with a brown horse.
Conventional training-free editing follows a data → data paradigm: inversion-based methods perform source → noise → target transfer, while inversion-free methods perform direct source → target transfer. Both approaches are tightly coupled to iterative procedures and cannot well exploit fast few-step sampling.
We propose viewing video editing as source-conditioned noise → target generation. This reformulation preserves the few-step sampling capability of streaming generators while injecting source-video conditions for controllability. Built on pre-trained streaming models (Self Forcing, LongLive), StreamGVE realizes this paradigm through the dual-branch fast sampling and attention manipulations.
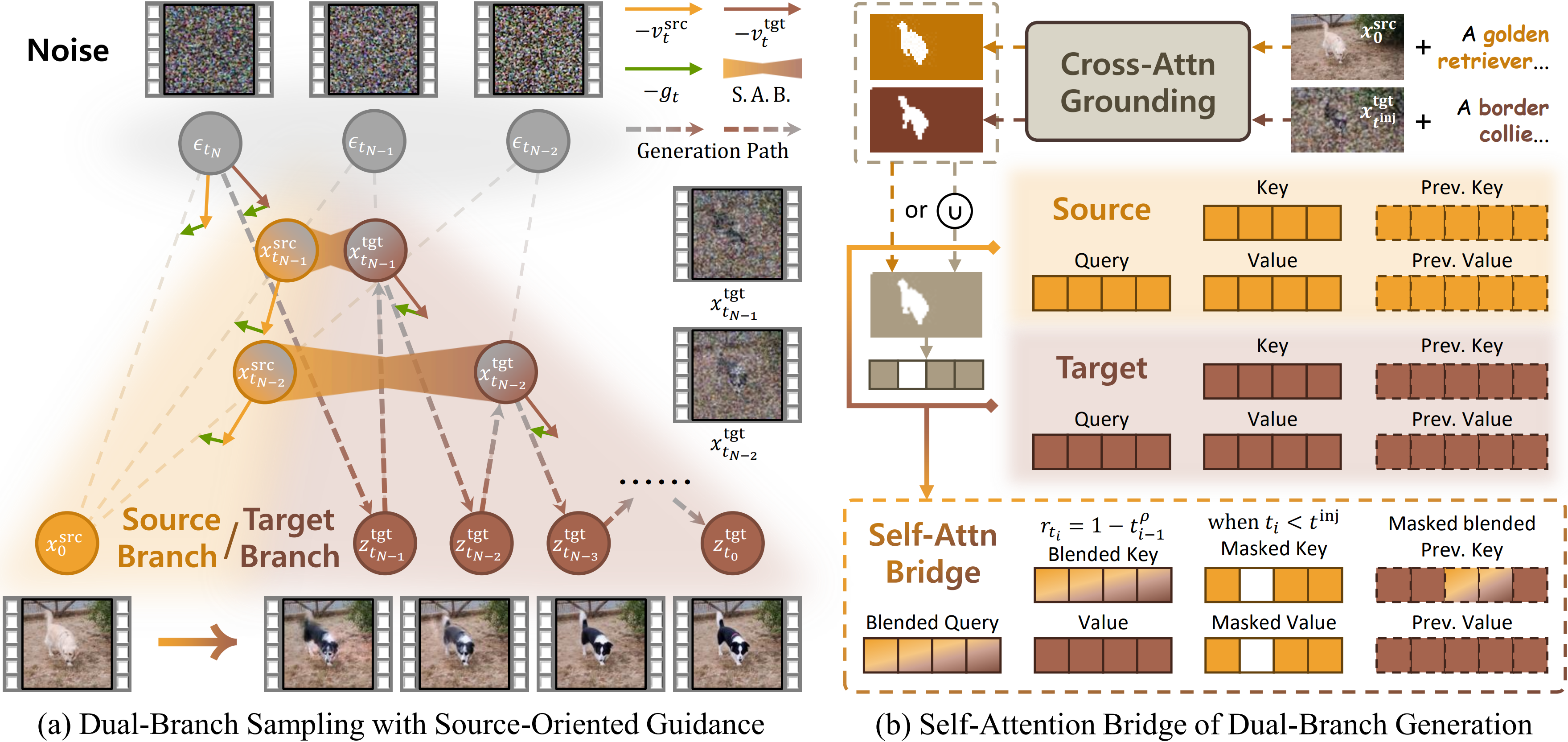
We extend stochastic few-step sampling to a dual-branch framework. Given a source video with its source prompt and target prompt, we denoise both in parallel under shared noise conditions:
This allows injecting source conditions at every denoising step:
We build a self-attention bridge between source and target branches to enable source condition injection. It consists of three components:
Query blending uses a timestep-dependent blending ratio to preserve the structure. The blending ratio $r_{t_i}$ increases from 0 to 1 as timestep decreases, with $\rho$ controlling the preservation strength:
Key blending stabilizes attention for editing consistency. We blend current keys and apply masked blending to previous-frame key:
Source KV injection provides background details when $t < t^{inj}$ (where $t^{inj} = 0.5$). The Iverson bracket $[t < t^{inj}]$ excludes the term when the condition is false. The final self-attention uses:
Grounding identifies editing regions via foreground-background attention differences. We compute the mask from the difference between averaged attentions over trigger words $\mathcal{T}$ and other words in the prompt $\mathcal{P}$, and use the Heaviside step function $H$ for binarization:
where $\phi \in \{\text{src}, \text{tgt}\}$ denotes the branch. We obtain $M^{\text{src}}$ at $t=0$ and $M^{\text{tgt}}$ at $t=t^{\text{inj}}$, then compute the union mask $M = \bigcup_{\phi} M^{\phi}$.
Boosting enhances trigger words inside editing regions. We modify the attention scores with weight $w_{p,q}$ controlled by $\omega$:
where $S(p,q)$ is the pre-softmax attention score, and $\omega$ controls editing strength.
To suppress stochastic artifacts, we compute the velocity prediction error by comparing against the linear-interpolation ground-truth:
This error is projected to the target branch via soft mask AMN(·) (Abs-Mean-Norm: channel-wise mean of absolute values, then min-max normalized) to correct the target velocity:
For fine-grained visual control, users can provide an edited first frame as a visual prompt. The framework treats it as a previously generated video chunk, incorporating detailed editing effects into target generation. It requires only one additional forward of the streaming generator.
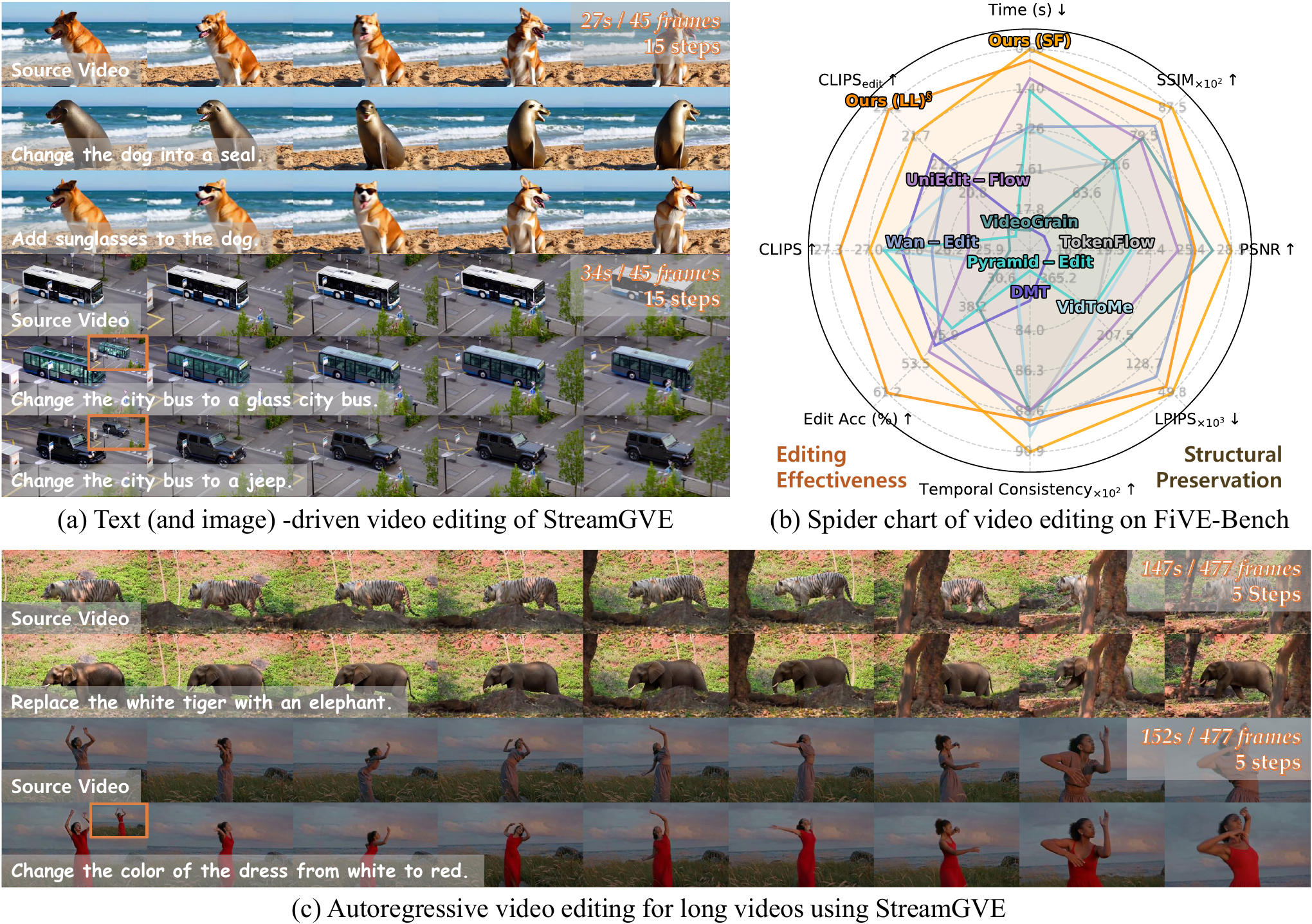
StreamGVE achieves state-of-the-art performance on FiVE-Bench, a comprehensive benchmark spanning 100 videos and 420 editing cases across six edit types: color alteration, material modification, object substitution with/without non-rigid deformation, addition, and removal.
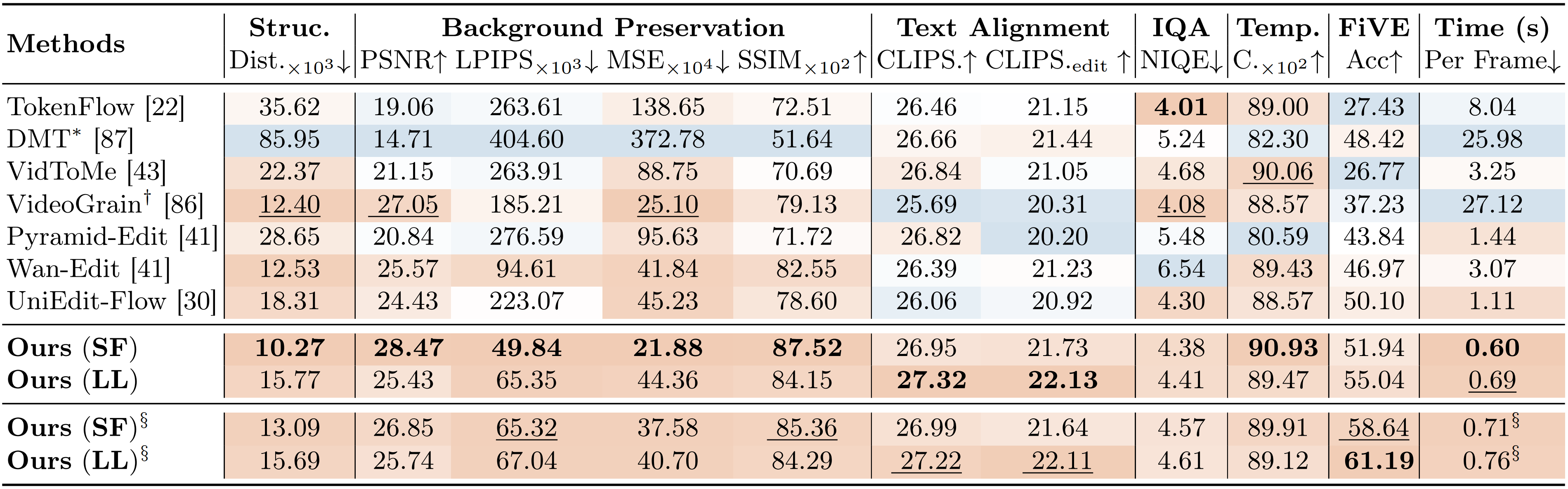
Comparison of different methods on short-video editing tasks.

Comparison of different methods on long-video editing tasks.

If you find this work useful, please consider citing, thanks!
@misc{jiao2026streamgvetrainingfreevideoediting,
title={StreamGVE: Training-Free Video Editing via Few-Step Streaming Video Generation},
author={Guanlong Jiao and Chenyangguang Zhang and Jia Jun Cheng Xian and Zewei Zhang and Renjie Liao},
year={2026},
eprint={2605.21466},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.21466},
}We sincerely thank the open-source community for their awesome work, particularly Self Forcing, LongLive, and UniEdit-Flow. 😊
Additionally, we would also like to thank the FiVE-Bench team for providing comprehensive baseline survey and great benchmark.